Python基本知识
🤖 AI 时代学习建议
这一章涵盖了 Python 的基础语法——变量、类型、数据结构、流程控制、IO 操作等。这些语法 AI 全都会写,你不需要死记硬背。
但请注意以下几点,它们是 AI 经常犯错或无法替你判断的:
- 动态类型的取舍:Python 不强制类型声明,这给了你灵活性,也埋了坑。AI 生成的代码经常忽略类型一致性问题
- 可变对象 vs 不可变对象:浅拷贝/深拷贝、列表作为默认参数的陷阱——这些 AI 时不时就会犯
- 数据结构的选择:什么时候用 list、什么时候用 dict、什么时候用 set?AI 倾向于用 list 解决一切,但正确的数据结构选择对性能和可读性影响巨大
安装
安装Python并不是一件很难的事情,请参照网络上的资料,我们不打算多做介绍。
值得一提的是,除了单独安装Python的发行版本,你还可以选择安装Anaconda,它包含了Python,同时还自带了很多方便的工具,相当于是一个打包后的工具集合。除此之外,Anaconda还可以提供虚拟环境,这在你学会Python之后的真正开发过程中会很有用。
Python版本
历史上Python2和Python3共存了很长一段时间,给初学者带来了很多不便,幸运的是,Python2已经渐渐退出历史舞台,所以初学者只需要学习Python3就好,确保你安装了最近的Python3版本即可。
Hello World
Python是一门解释性的脚本语言,如果你用过MATLAB,不难理解什么是解释性语言。C++是一门编译性语言,需要先编译才能运行。相比之下,解释性语言的运行方式灵活的多。
第一种运行Python的方式
在命令行中直接运python.exe,你将进入 Python 的REPL,直接打印hello world!
什么是REPL?
读取-评估-打印循环(REPL),也称为交互式顶层或语言外壳,是一种简单的交互式计算机编程环境,它接受单个用户输入、执行它们并将结果返回给用户; 在 REPL 环境中编写的程序是分段执行的。 该术语通常指的是类似于经典 Lisp 机器交互环境的编程接口。 常见的例子包括命令行 shell 和编程语言的类似环境,该技术非常具有脚本语言的特征。 A read–eval–print loop (REPL), also termed an interactive toplevel or language shell, is a simple interactive computer programming environment that takes single user inputs, executes them, and returns the result to the user; a program written in a REPL environment is executed piecewise. The term usually refers to programming interfaces similar to the classic Lisp machine interactive environment. Common examples include command-line shells and similar environments for programming languages, and the technique is very characteristic of scripting languages.
虽然REPL是脚本语言的特征,但并非只有Python/Javascript这样的脚本语言才有REPL,很多编译语言也提供了这样的功能,比如scala。如果你用过ROOT https://root.cern/install/ ,你会发现它其实就是C++的REPL。
ROOT是通过LLVM技术对C++代码进行了运行时编译,并非使用了传统的编译器,所以才能executed piecewise(一段段代码的执行)。
第二种运行Python的方式
你也可以把Python代码写在一个文件里面,然后用如下命令运行:
其他运行Python的方式
Python可以很方便地集成到其他开发工具中:Pycharm、VS Code、jupyter notebook等等,这些IDE或编辑器会帮助我们调用Python解释器。
注释
和C++一样,Python里面也有两种注释:一种是单行注释,另一种是多行注释。
变量
与C++不同,在Python里面你可以直接使用任何变量,不需要显示指定变量的类型,也不需要提前声明,这和MATLAB里面的用法类似。
容易看出,我们先后给变量a赋值了整数类型,字符串类型和浮点数。变量的类型随时有可能变化,这和C++不同。那么我们怎么知道一个变量在某个时候的具体类型呢?可以利用type函数:
 消失的指针
消失的指针
C++中存在指针,Python中指针消失了。在C++中我们会关心传递一个参数的时候是传递的指针还是值,或者引用,那么在Python中是否有类似的问题?在Python里面,对象是存储在内存中的,每个变量都是指向对象的引用(为了理解方便,也可以当作指针)。
变量a,b和对象的关系如下图所示:
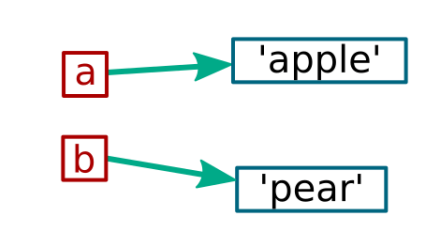
如果你把b赋值给了a,
那么它们之间的关系会变成下面这个样子:
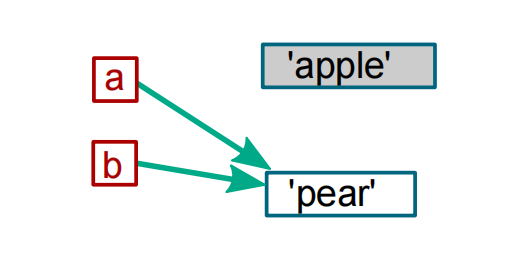
所以变量都是引用。那么问题来了,上图中的情况用C++里面的情况类比,相当于a指针指向了b,a指针原来指向的对象不再使用了,也没有其他方式可以再访问了,如果没有提前删除,'apple'就成了孤岛,这不就是内存泄漏吗?
消失的内存泄漏
如果你只学过C/C++语言,那么这可能是你第一次听说“垃圾回收”这个词。垃圾回收是现代编程语言中非常重要的技术,Java,Python,Javascript等编程语言都有垃圾回收机制。垃圾指的是那些程序不再需要的内存对象,回收就是系统自动把这些内存删除掉。因此,在具有垃圾回收的语言里你不用再担心内存泄漏啦!
当然,你依然可以选择手动删除不需要的对象,删除方式和C++类似:
消失的括号
在Python里面我们不需要使用大括号来包裹一个代码块,具有相同缩进的代码会自动属于一个代码块。所以大括号在这里消失了。
Python中也可以加分号,但是行尾分号是可选的,如果你不在一行内写多个语句,那么完全没有必要使用分号。
类型
类型系统是任何编程语言的基础,下面是Python里面内置的一些数据类型,
| 类型 | 例子 |
|---|---|
| int | a = 1 |
| float | a = 0.5 |
| str | a = "hello" |
| bool | a = True/False |
| complex | a = 1 + 2j |
| bytes | a = b"hello" |
| set | a = set() #空集合 |
| list | a = list() #空列表 |
| tuple | a = tuple() #空元组 |
| dict | a = dict() #空字典 |
在Python3中float是64位的。int是动态长度的长整型,理论上支持无限大的数字。bytes类型就是二进制类型,将数据保存为字节数组,一个字节数组其实就是二进制串。字符串前面加上 b 就代表该字符串是用字节数组的方式存储的。在Python里面没有char类型。complex是复数类型,在C++内置类型中也是没有的。
Python中用True和False来代表bool值的真和假。
类型推断
你已经发现,当我们给变量a赋值的时候,并不需要指明a是什么类型,Python会自动知道你赋值的类型是什么,这就是类型推断。
Python会自动推断赋值表达式右侧的数据类型,然后给变量设置对应的类型,类似C++中的auto关键字的作用。类型推断是编程语言中很重要的一个特性,优雅的编程语言都会支持类型推断。
 C++中的auto关键字也是在后期的标准中才添加进去的,早期的C++编译器并不支持auto关键字。
C++中的auto关键字也是在后期的标准中才添加进去的,早期的C++编译器并不支持auto关键字。
字符串
关于引号
Python里面有个非常聪明的设计:单引号和双引号都可以表示引号,效果等价,但不能同时生效。不能同时生效的意思是,如果你用单引号包围一个字符串,那么在字符串内的双引号就是普通字符,就不用加反斜杠了,反之亦然。
此外,还有一种三引号(三个单引号或三个双引号等价),三引号可以包含多行字符串:
多行字符串会把每行的尾部自动加上换行符号,然后合并成一个字符串,多行字符串在你处理长字符串的时候可能有用。
原始字符串
原始字符串是 “所见即所得” 的字符串,你只需要在字符串之前加上r,就不用再对字符进行转义了。这在处理Windows下的文件路径时尤其有用,可以提供很多方便:
格式化字符串
字符串格式化虽然不是什么复杂的功能,但却非常常用。在Python里面有以下几种方法:
a = "I am"
b = 18
c = "years old."
# 方法一: 很类似C的风格
s = "%s %d %s" % (a, b, c)
# 方法二.a: 自动识别格式,
s = "{0} {1} {2}".format(a, b, c)
# 方法二.b:
s = "{} {} {}".format(a, b, c)
# 方法二.c: b的一个变体,可以自己控制顺序
s = "{0} {1} {2}".format(a, b, c)
# 方法二.d: 可以利用名字格式化,更加可读
s = "{prefix} {age} {suffix}".format(prefix = a, age = b, suffix = c)
# 方法二.e:利用字典
data = {"prefix":"I am", "age":18,"suffix":"years old."}
s = "{prefix} {age} {suffix}".format(**data)
# **代表把字典的key-value解开,按照单独的key-value pair 传递,效果和方法d等同
# 方法三.a
s = f"{a} {b} {c}"
# 方法三.b
# 支持表达式
s = f"{a} {3*6} {c}"
# 方法三.c
# 你可以直接在大括号里调用函数,实际上,你可以直接在这里“写代码”。
s = f"{a} {get_years_old()} {c}"
# 方法三.d
# 对浮点数进行格式化,与C++类似。(三种方法都可以,仅以第三种为例)。
a = 3.5
s = f"{a:5.2f}"
推荐使用第三种方式,当你习惯之后,你会忘掉前两种 。
。
数据结构
set、list、tuple、dict都是容器类型,元组tuple就是不可修改的列表list,除此之外和list等价。与set,list,dict相对应,C++的标准库里也支持list,set,map等类型,但远没有在Python里使用起来方便。
创建
添加元素
# 集合
a = set()
a.add(1)
a.add("ok")
# 列表
a = []
a.append(1)
a.append("ok")
# 字典
a = {}
a.update({"name":"wang"})
a.update({"age":18})
删除元素
# 集合
a = set()
a.add(1)
a.add("ok")
a.remove("ok")
# 列表
a = []
a.append(1)
a.append("ok")
a.remove("ok")
# 字典
a = {}
a.update({"name":"wang"})
a.update({"age":18})
del a["name"]
遍历元素
遍历这些容器的时候我们需要用到 in 这个运算符,list,tuple,set的遍历方式如下:
字典比较特殊,它每个元素其实是个 key-value的pair,所以按照排列组合,你有很多种去迭代它的方式:
a = {}
a.update({"name":"wang"})
a.update({"age":18})
for x in a: # 默认迭代 keys
print(x)
# output:
# name
# age
for x in a.keys():
print(x)
# output:
# name
# age
for x in a.values():
print(x)
# output:
# wang
# 18
for k,v in a.items(): # k,v = (k,v)
print(k,v)
# output:
# name : wang
# age : 18
items() 函数返回的元素是长度为2的元组,元组在任何时候都可以直接展开成多个元素。
访问元素
- 按下标访问列表
 访问元组的方式与list相同,但set类型不可以用下标访问,思考一下为什么?
访问元组的方式与list相同,但set类型不可以用下标访问,思考一下为什么?
- 按key访问字典
- 切片 slicing
首先我们可以用range函数来创建一个连续整数列表,
a = list(range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = list(range(0,10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a = list(range(0,10,2)) # [0, 2, 4, 6, 8]
range函数生成的其实是迭代器,关于什么是迭代器后面会仔细讲,这里你只需要知道必须用list函数把迭代器包裹起来才能转换成列表。
接下来我们看一下如何访问列表的一部分:
a = list(range(10)) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
a[0:1] # [0]
a[2:4] # [2,3]
a[2:] # [2, 3, 4, 5, 6, 7, 8, 9]
a[:3] # [0, 1, 2]
a[-2:-1] # [8]
a[:] # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
访问一个列表的切片真的相当灵活,想想在C++里实现以上功能你需要多少行代码
 浅拷贝与深拷贝
浅拷贝与深拷贝
上面最后一行代码 a[:] 看起来什么也没做,其实不然,它的用途一点也不小。记住我们上文讲的,Python里面的变量都是引用,所以当你要复制一个变量的时候,用等号赋值仅仅赋值了引用,我们叫做浅拷贝;如果你复制了一个变量的内存对象,那才叫深拷贝。
# 浅拷贝
a = [1,2,3]
b = a
b.append(4)
print(a) # [1, 2, 3, 4]
print(b) # [1, 2, 3, 4]
# 深拷贝
# 如果你不想遍历a然后一个个把值赋给b,那么就要用下面的方式
a = [1,2,3]
b = a[:] # 或者 b = list(a)
b.append(4)
print(a) # [1, 2, 3]
print(b) # [1, 2, 3, 4]
类型转换
类型之间的转换方法如下表:
- 转成str
任何对象都可以转成str, 你还可以利用上文提到的格式化字符串方法把其他类型转成字符串。
- 转成int/float
并不是所有类型都可以转成int/float,它们必须符合一定的格式。
- 转成bool
其他类型转换成bool类型的时候,只有为零为空的时候才会被转换成False,其他情况一律转换成True,这一点需要注意。
bool(set()) # False
bool([]) # False
bool({}) # False
bool("") # False
bool(0) # False
bool(0.0) # False
所以当你看到如下的结果,就不必感到惊讶。
- 转成bytes
其中bytes类型可以被当作特殊字符串,在字符串前面加上 b 就代表bytes类型。想一想ASCII编码,每个字符就是一个byte,所以ASCII编码下bytes和str没有区别,但是非ASSCII编码下就不一样了,如果将汉字字符串转成bytes,则需要考虑编码方式,直接在前面加b会报错。
如果要将int或者float转换成bytes,则需要考虑到诸如字节数,大端或小端等细节。
运算符和表达式
运算符和表达式是基础内容,可参考以下链接:
绝大部分运算发符在C++之中都有对应,这里值得一提的是Python中的逻辑运算符直接使用: and、or、not,理解起来非常方便。
另外,Python中还有一个成员运算符:in,用来判断一个元素是否在另一个容器里面。这与 for 循环中使用的in有些像,但功能不太相同。
流程控制
条件语句和循环控制语句比较基础,和C++中没有太大区别,可以直接参考以下链接:
下面给出一些代码示例。
if-else
num = 5
if num == 3: # 判断num的值
print('boss')
elif num == 2:
print('user')
elif num == 1:
print('worker')
elif num < 0: # 值小于零时输出
print('error')
else:
print('roadman') # 条件均不成立时输出
while
for
Python中也支持 continue 也 break 语句,和C++中的使用方法一样。
标准库/第三方库
引用模块
标准库是编程语言中非常重要的一部分,标准库就是那些你不需要单独安装就可以使用的库。在C++中我们使用便准库以及第三方库中的内容时需要include相对应的头文件,在Python中我们用 import 这个关键字。
与C++不同,引用模块之后,使用模块中的任何内容都需要加上引用的名字,这有点类似C++中的命名空间,但又不完全相同。Python还允许你给模块定义别名:
不过,使用别名的时候要小心,不要随便定义一个名字,否则别人无法读懂你的代码。实际开发中已经形成了很多默认的规范,不同的模块会有固定的别名,比如:
有的时候一个模块中还包含子模块,你可以用 “.” 引用子模块的内容,或者使用 from 导入:
使用模块
在C++中如果你想使用第三方库,你会怎么做?
在Python中使用第三方库非常简单,需要用到一个包管理工具 pip,这个工具在你安装Python的时候默认就被安装好了。如果你用过linux系统,那么你一定接触过apt,yum等包管理工具,当你安装软件的时候,不用再去网络上自己下载和手动安装,直接用包管理工具一键安装即可。pip的工作原理也是如此。
pip是一个用Python写的用于安装和管理包的包管理系统。它连接一个叫做Python Package Index的在线公共包存储库。它通过配置,也可以连接其它包库。
常用命令
安装包:
安装过程中会自动帮助你安装依赖。若需要指定特定的版本安装: force-reinstall 用于指示重新安装指定版本的包。也可以指定版本的范围安装:卸载包:
常用标准库
os
os模块是非常常用的模块,这里有很多功能
import os
os.remove("/path/to/test.txt") # 删除文件
os.rmdir("/path/to") # 删除文件夹
os.chdir("/path/to") # 改变当前程序的工作目录
os.makedirs("/path/to") #创建多级文件夹
os.mkdir("/path") # 创建单个文件夹
os.listdir("/path") # 列举出文件夹中的内容
os.system("python code.py") # 运行系统命令
"""
os.path用于处理和文件路径相关的任务。
linux和windows的文件路径分隔符不一样,这在使用中带来很多不便,
使用这一模块将会大大方便你的操作。
"""
os.path.sep # 这是一个字符,是当前系统下默认的路径分隔符,windows下就是 \。
os.path.split("\\path/to/file.txt") # 把文件路径分割成目录和文件名两部分
os.path.isdir("/path") # 判断是不是文件夹
os.path.isfile("/path/file") # 判断是不是文件
os.path.join(["/path", "subpath", "file"]) # 把list里的内容用 os.path.sep 连接起来
这里特别强调一下,os.system() 可以直接运行任何系统命令,这是python和系统交互的一种方式,非常方便,不过这种方式你没办法获得系统程序的标准输出内容。如果你想无缝衔接系统其他程序,可以使用 subprocess 这个模块。
sys
运行python的时候可以传入命令行参数,这个参数我们如何获得呢?用sys模块即可。
# python code.py arg1 arg2
import sys
len(sys.argv) # 参数数量 3
sys.argv[0] # 文件名 code.py
sys.argv[1:] # 其他参数 arg1 arg2
math
这里有你需要的数学函数,不用多做介绍。
time
import time
start = time.time()
time.sleep(3) # 3 seconds
end = time.time()
print(end-start)
# 输出: 3.013838768005371
datetime
from datetime import datetime
now = datetime.now()
now.strftime("%Y-%m-%d %H:%M:%S %f") # 输出格式化字符串
dt = datetime.strptime("2022-01-01", "%Y-%m-%d") # 从字符串构造
random
import random
random.seed(123) # 初始化种子
random.random() # [0,1) 之间的随机数
random.choice([1,2,4,5,6,7]) # 从一个列表中随机选择一个对象
random.choices([1,2,3,4,5,6], k=2) # 随机选择k个结果
random.randint(1,5) # 返回 [1,5]区间的随机整数
random.gauss(0,1) # 从高斯分布采样。也支持其他各种分布
random.shuffle([1,2,4,5]) # 对列表内的元素进行随机排序
argparse
这个模块用于处理命令行参数,
import argparse
# 创建对象
parser = argparse.ArgumentParser()
# 定义你希望传入的命令行参数
# 输入的时候按照 --arg1=value1 的格式传入,与顺序无关
parser.add_argument("--arg1", type=str, default="arg1")
parser.add_argument("--arg2", type=int, default=1)
# 开始解析命令参数,如果传入的参数和预定义的不匹配会报错
args = parser.parse_args()
# 如果你希望传入未知参数的时候不报错
args,unknown_args = parser.parse_known_args()
# 使用参数
print(known_args.arg1)
copy
glob
前文提到了用 os.listdir() 来查看一个文件夹中的内容,如果你想: - 获取文件的完整路径 - 支持用通配符筛选文件 - 支持递归访问子目录
那么你可以使用glob这个模块。
import glob
glob.glob("/path/to/*.txt") # *匹配一个或多个字符
glob.glob("/path/to/**/*.txt") # ** 匹配所有文件、目录
glob.glob("/path/to/**/*.txt", recursive=True) # 递归匹配所有子目录内容
IO和文件操作
- 读文本文件
f = open("test.txt", encoding="utf-8") # 为了不乱码,最好每次都指明 encoding
f.readline() # 一次读取一行,包含换行符
# 重新设置文件读取指针到开头
f.seek(0, 0)
#方法用于从文件读取指定的字节数,如果未给定或为负则读取所有,该方法通常用于读取二进制文件
f.read()
f.close()
- 写文本文件
f = open("test.txt", 'w', encoding="utf-8")
f.writeline("a\n")
f.write("") 方法用于向文件中写入指定字符串.
f.close()
- 遍历文件每一行
f = open("test.txt", encoding="utf-8")
for line in f.readlines():
print(line)
for line in f:
print(line)
# 以上两种迭代方式看起来是等价的,但却有所区别。
# 第一种是把所有的行按照list的方式读入内存,然后遍历。
# 第二种直接对f进行迭代,这个时候文件中的每一行并没有预先被读入内存。
# f默认具有迭代器属性,关于什么是迭代器,后面会再做具体介绍。
f.close()
- 读二进制文件
filepath='x.bin'
binfile = open(filepath, 'rb') # 打开二进制文件
size = os.path.getsize(filepath) # 获得文件大小
for i in range(size):
data = binfile.read(1) # 每次读取一个字节,返回的类型是 bytes类型。
print(data) # 如果在这里你想看到是数值类型或字符串,那么你可以用类型转换方式
binfile.close()
- 写二进制文件
f = open('x.bin', 'wb'):
f.write(b"test") # 写入的必须是 bytes 类型,如果你想写入整数或浮点数,需要做一次类型转换
"""
python提供了struct模块,可以很方便地在数值和bytes之间进行转换
"""
import struct
struct.pack("i", 1) # 把整数 1 转换成bytes
struct.unpack("i", b'\x01\x00\x00\x00') # 把bytes转换成整数
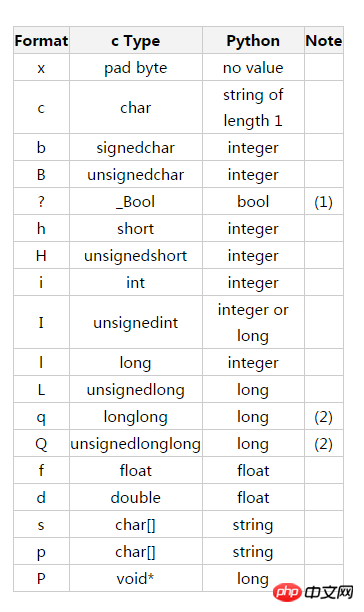
 struct 用法
struct 用法
语法糖
语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
- 条件赋值
虽然Python中没有问号和冒号组成的三目运算符,但是可以用if else的条件赋值代替.
- 多元赋值
- zip 迭代
如果你想迭代两个等长的数组,在C++中你需要一个索引,然后从两个数组分别取值,在python里面你也可以这做,也可以用zip函数。
a = ["name","age"]
b = ["wang",18]
data = {}
for i in range(len(a)):
data.update({a[i]:b[i]})
# 更优雅的写法
for x,y in zip(a,b):
data.update({x:y})
zip把两个列表压缩成一个列表,里面的每个元素是元组。
- enumerate 迭代
- 列表推导式
如果我们想把一个列表中的每个元素变成平方:
a = [0,1,2,3,5,6]
b = []
for x in a:
b.append(x**2)
# 更优雅的写法
b = [x**2 for x in a]
# 还可以加条件
b = [x**2 for x in a if x > 0]
- 集合推导式
- 字典推导式
a = ["name","age"]
b = ["wang",18]
data = {}
for x,y in zip(a,b):
data.update({x:y})
# 应用字典推导式,还可以更简便
data = {x:y for x,y in zip(a,b)}
- 大于和小于
- with关键字
在C++里,如果你要打开一个文件,你总要记得关闭。Python里面也有打开和关闭文件的操作,不过,利用with as关键字后,你可以不必手动关闭文件了。
f = open("text.txt")
for line in f.readlines():
print(line)
f.close()
# 更优雅的写法
with open("text.txt") as f:
for line in f.readlines():
print(line)
 Python中还有很多的语法糖,这些语法糖能帮助我们把代码变得非常简单。
Python中还有很多的语法糖,这些语法糖能帮助我们把代码变得非常简单。