函数
🤖 AI 时代学习建议
函数是编程的基本构建块。AI 擅长写单个函数,但在以下方面经常出问题:
- 函数边界的划定:一个函数该做多少事?什么时候该拆分?这是设计判断,不是语法问题
- 副作用的控制:纯函数 vs 有副作用的函数,AI 经常写出隐含副作用的代码
- 高阶函数和闭包:理解这些概念,你才能看懂 AI 生成的复杂代码,也才能判断它是否正确
- 装饰器:这是 Python 的精华之一。AI 会用装饰器,但你需要理解它的原理,才能在 AI 犯错时发现问题
什么是函数?
函数在数学上有着清晰的定义,常用的表达形式如下:
其中x是自变量,y是因变量(返回值),f是对应法则。编程语言中的函数和数学上的函数在本质上是一样的,但也有一些明显的区别。我们先看一下C++中函数的定义方式,
C++中的函数的参数和返回值都定义了类型,这是和 \(y=f(x)\) 最大的区别。数学上的函数处理的都是“数”,所以不需要特别指出类型。从这个角度看,编程语言中的函数在形式上其实要比数学上的函数复杂:通过对参数数量、类型,返回值类型的各种排列组合,可以给出丰富和复杂的函数定义。如果我们忽略一个函数的具体实现,那么以下三点就是函数最重要的属性:
- 函数名
- 输入参数列表
- 输出/返回值
定义函数
在Python中定义函数利用如下语句。
这个函数什么也没做,没有输入也没有输出,调用它不会产生任何效果。但你不要小看它,正所谓麻雀虽小,五脏俱全,这个函数包含的内容一点不简单。我们可以用 dir() 函数查看任何一个函数或对象的细节:['__annotations__',
'__call__',
'__class__',
'__closure__',
'__code__',
'__defaults__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__get__',
'__getattribute__',
'__globals__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__kwdefaults__',
'__le__',
'__lt__',
'__module__',
'__name__',
'__ne__',
'__new__',
'__qualname__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__']
dir() 方法像是一个透视镜,是一个非常有用的工具。
一个普通的函数已经自带了这么内容?没有想到吧,这看起来和C++中的函数完全不同。
一切皆对象
C++虽然也是面向对象的编程语言,但是远没有其他一些面向对象的编程语言那样极端。在Python里面一切都是对象。这句话的意思是:任何变量——包括整数,浮点数,字符串,任何函数,以及任何类都是对象。比如我们同样用dir方法查看一个整数,你会发现它同样包含了很多内容。
['__abs__',
'__add__',
'__and__',
'__bool__',
'__ceil__',
'__class__',
'__delattr__',
'__dir__',
'__divmod__',
'__doc__',
'__eq__',
'__float__',
'__floor__',
'__floordiv__',
'__format__',
'__ge__',
'__getattribute__',
'__getnewargs__',
'__gt__',
'__hash__',
'__index__',
'__init__',
'__init_subclass__',
'__int__',
'__invert__',
'denominator',
'from_bytes',
'imag',
'numerator',
'real',
'to_bytes']
这些双下划线开头和结尾的方法被成为魔法方法,是Python默认为我们创建的。比如,C++中的类当我们不显示定义构造方法的时候,编译器会帮助我们创建一个默认构造方法。很明显在Python中编译器帮我们做了更多的事情,即使是一个什么也不做的函数,都会包含丰富的魔法方法。
关于一切皆对象的概念,请慢慢去体会,它会导致与C++中完全不一样的开发体验。因为一切皆对象的缘故,在Python中你看到的内置类型和C++是有所区别的。比如int类型,在C/C++里面它只占用内存中的四个字节,但是在Python里它还包含了对象头:
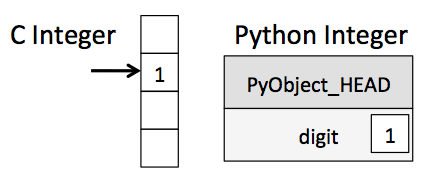
魔法方法
魔法方法通常都会被编译器自动调用,并且不同对象的默认魔法方法是不同的,上述函数和整数变量的魔法方法就有很多不同。我们以 __add__ 这一魔法方法为例,看一下它的用途:
不过,Python并没有阻止我们手动去调用这些方法:
了解这点之后,你就可以自己给任何一个对象定义 __add__ 方法,在C++里,相当于你重载了 + 这个运算符。这一道理对其他任何魔法方法都适用,Python中的魔法方法非常多,在此就不一一列举了,可以在具体实践中慢慢学习。
函数参数
了解完魔法方法之后,我们开始定义一些真正有用的函数,并研究一下它的性质。
这个函数只负责打印三个输入变量。这里我们并没有定义三个输入参数的类型,因为Python是动态类型语言,会在运行时去判别变量的类型,不需要在定义的时候显示指定。这给开发带来了很多灵活性。位置参数和key-value参数
在调用任何一个方法或函数时,都可以有以下三种方式来传递参数:
1. 首先,我们可以按位置传入每个参数,这和C++并没有什么不同。 2. 其次,我们也可以按照参数名和值的键值对方式传入参数,当你指定参数名的时候,顺序就变得不重要了。 3. 混合使用两种方式传入参数:前面是按照位置传入,后面按照key-value的形式传入。那么,是不是可以随便混用呢?试一试:
File "C:\Users\haipw\AppData\Local\Temp/ipykernel_47416/3420492099.py", line 1
f(1,b = 2, 3)
^
SyntaxError: positional argument follows keyword argument
仔细阅读错误提示,它已经告诉你答案:SyntaxError: positional argument follows keyword argument. ,Python不允许这样做。
可变数目参数
以上方法已经够灵活了,但是程序员的需求是无止境的,有时候我们还想更灵活一些。上面定义的函数,只能接受三个参数,如果我们想随便给一个函数传入任意数量的参数呢?(有点太随意了,但Python可以满足你):
def f(a,b,c, *args, **kwargs):
print(a,b,c)
print("args:")
for k in args:
print(k)
print("kwargs:")
for k,v in kwargs.items():
print(k,v)
f(1,2,3,4,5,6,x=1,y=4)
# 1 2 3
# args:
# 4
# 5
# 6
# kwargs:
# x 1
# y 4
*args 把所有未知的 positional arguments收集到一个列表里面,**kwargs把所有未知的keyword arguments收集到一个字典里面。星号在这里可以理解为 收集 或者 打包压缩。
函数的返回值
在c++里面,函数只能有一个返回值,如果你想返回多个值,它们必须被包含在一个对象里面。在Python里也是如此,但看起来略有不同:
好像我们可以返回多个值啊?打印一个试试:
从输出的结果看,我们得到的其实是一个元组(注意他们是被括号包裹起来的,是元组的形式)。所以虽然看起来你返回来多个结果,但是Python又偷偷做了一层处理,返回的还是一个。最终,你可以直接用一个元组变量去接收这个返回值,也可以利用多元赋值的性质,直接把元组赋值给三个变量。
第二种写法,看起来和你返回了多个结果没什么区别。试想一下,如果让你写一个函数返回一个整数,一个数组和一个字符串,在C++里面你会怎么实现?而在Python里面,你甚至都不用想去如何实现,直接返回就是了。
类型注解
函数的参数和返回值也是动态类型,这虽然很灵活,但是也会带来很多问题,让一些隐藏的bug不容易被发现。因此,Python在发展中引入了类型注解,可以像C++一样给函数的参数和返回值添加类型,比如:
不过这里需要强调的是,在编译和执行额阶段Python并不会关心类型注解,你依然可以传递任何类型的数据进来,就和没有类型注解一模一样。那么这些注解的作用是啥?答案如下: - 给人看,增加代码的可读性,可以有效减少误用,减少Bug的数量。 - 给静态代码分析工具看,如果你添加了类型注解,Linter( 静态代码分析工具)就可以在编译运行之前帮你检查错误,并且给与一定的提示。
下面是VSCode中给出的错误提示:
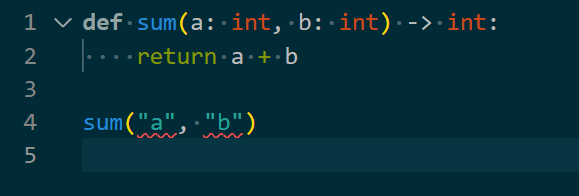
请注意,上图中的代码是可以正确被Python运行的,因为字符串也可以相加,但显然这不符合代码设计者的意图,如果你希望同时能接受字符串的输入,那么可以这样注解,这样Linter就不会报错了。
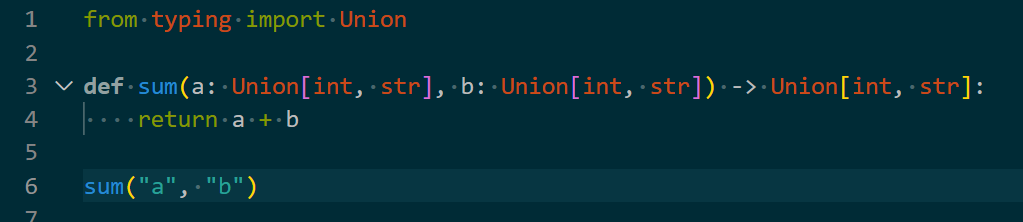
在 Python3.10 及以上版本中你还可以这样做:
 静态类型和动态类型的编程语言各有优缺点,静态类型检查使得动态类型的编程语言也可以具有静态类型的优势。
静态类型和动态类型的编程语言各有优缺点,静态类型检查使得动态类型的编程语言也可以具有静态类型的优势。

函数编程
函数编程和面向过程编程、面向对象编程一样,都是一种编程范式,有的时候也可以理解为一种编程风格,它们并没有严格意义上的使用界限,在C++里我们写代码很多时候都是混合使用面向过程编程和面向对象编程两种风格。我们先来看一个函数编程的定义:
函数编程使用函数作为代码的主要构建单元。和过程编程不一样,函数编程范式把函数当作对象来处理:可以被当作参数传递,可以在执行的过程中动态创建函数。 Functional programming (FP) uses functions as the main building blocks. Unlike procedural programming, the functional paradigm treats functions as objects that can be passed as parameters, allowing new functions to be built dynamically as the program executes.
函数在任何编程语言里都支持,但并不是任何编程语言都适合函数编程。比如把函数本身当作参数(不是复杂的函数指针)和动态创建函数,这在C++中就无法实现。Python是支持函数编程的语言,函数在Python中就是对象,是一等公民。
函数编程的特点
函数编程偏爱纯函数
并非说使用函数就算作函数式编程,函数编程喜欢用更接近数学上定义的纯粹的函数:接受输入,返回输出,多次重复调用返回的值完全唯一确定,并且不会有其他的附加影响。
我们先举一个C++中函数的例子,
从功能上看,这是个比较简单的函数,但是因为传入了指针的缘故,调用完这个函数后你不确定 a 的值是否会被改变。这就是我们所说的附加影响:side effects。在数学中我们使用一个函数的时候,是不需要担心这些东西的。下面是一个纯函数的例子:
函数编程风格会尽量避免side effects,使用纯函数只是其中的一种,除此之外函数编程尽量使用不可变的对象,不可变的对象是指创造之后就不能被修改的对象,这就是list和tuple的区别。使用不可修改的对象也会避免导致side effects。
函数作为对象
函数作为一等公民,所有你对其他变量能操作的事情都可以对函数进行操作,比如:
赋值
创建
在C++中我们必须要先定义一个函数才能够使用它,Python中你可以直接用lambda表达式创建函数:
# example 1
sum = lambda x,y: x+y
sum(1,2)
# example 2
import math
sin2 = lambda x: math.sin(x)**2
sin2(math.pi/3)
lambda表达式就是匿名函数,你可以把它赋值给任何变量,lambda表达式只能定义一行表达式能完成的函数,太复杂的函数还是得用 def 来定义。不过考虑到Python语言的简洁性,一行代码你能完成的事情也远远超过你现在的想象。
添加到列表
作为函数参数
函数作为参数有几个比较常用的例子。
排序
names = ["zhang","wang","li", "zhao"]
# 默认排序
sorted(names) # ['li', 'wang', 'zhang', 'zhao']
# 自定义排序函数,这里用len函数
sorted(names, key=len) # ['li', 'wang', 'zhao', 'zhang']
# 用自己创建的函数
sorted(names, key=lambda x: -len(x)) #['zhang', 'wang', 'zhao', 'li']
map
map操作就是对每个元素都应用一次函数,map会返回一个迭代器对象,可以用list将其转换成列表。
names = ["zhang","wang","li", "zhao"]
list(map(lambda x: x + "#", names))
# ['zhang#', 'wang#', 'li#', 'zhao#']
作为函数返回值
def add_N(n:int):
def add(x):
return x + n
return add
add_1 = add_N(1)
add_1(1) # 2
add_1(3) # 4
add_1024 = add_N(1024)
add_1024(3) # 1027
闭包
闭包是个很有意思的概念,值得特殊讲一讲。 上面函数作为返回值的例子里其实就用到了闭包,我们重新再看一下这个函数:
add_N 内部的这个add函数,引用了它外部的变量(也就是add_N)的参数n。当我们把add这个函数返回的时候,它好像 携带 了n这个参数一样,在后面的使用中依然能正确使用它的值。
我们知道函数都有自己的作用域,变量 n 在 add_N 这个函数的作用域之内,但是不在 add 这个函数的作用域内。但是当我们返回 add 这个函数的时候,它把其所引用的父作用域的变量也带上了,这就是闭包。
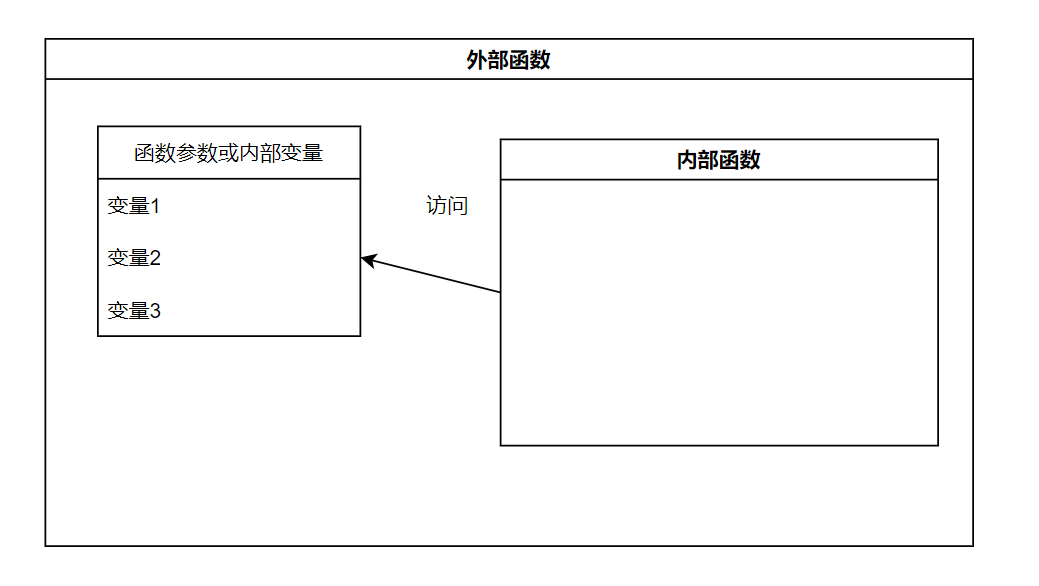
 关于这种作用域的性质,看起来有没有一点熟悉呢?想想在面向对象编程里面,一个对象有自己的作用域,对象内部的方法可以随便访问对象内部的属性。如果你把对象内的方法当作函数来看,你会发现对象属性也并不在函数的作用域内:
关于这种作用域的性质,看起来有没有一点熟悉呢?想想在面向对象编程里面,一个对象有自己的作用域,对象内部的方法可以随便访问对象内部的属性。如果你把对象内的方法当作函数来看,你会发现对象属性也并不在函数的作用域内:
既然在Python中函数本身就是一种对象,那么闭包的支持也就变得不难理解了。并且闭包在某种程度上让函数替代了类的工作,这也正是函数编程范式所追求的:尽量使用函数,而不是类。
利用闭包确实能做很多事情,下面有个小例子:
这是生成复合函数的一个函数,如果你经常需要连续调用几个函数,那么不妨把他们组合起来,这样会让你的代码更简洁。
迭代器
函数编程喜欢使用迭代器,实际上我们前面已经使用了很多次迭代器了,在Python中任何对象都可以成为迭代器,迭代器可以看做是对象的一个属性。
要把对象/类创建为迭代器,必须为对象实现 __iter__() 和 __next__() 方法。__iter__() 方法可以执行操作(初始化等),但必须始终返回迭代器对象本身。__next__() 方法也允许您执行操作,并且必须返回序列中的下一个项目。
所以列表,元组,字典等等很多对象都是迭代器,只要实现了上述方法,你也可以自己定义迭代器。
生成器
生成器是一种特殊的迭代器,也是可迭代的对象,不过这种对象有些特殊。现在考虑有一系列的数据需要处理,有以下两种处理的方法:
- 全部加载到内存,然后逐个处理
- 一次只加载一个对象到内存,处理完后再加载下一个
很显然,第二种更加节省内存资源,是一种“懒加载”的方式——只有当需要的时候才加载数据。
def get_array():
arr = [0,1,2,3,4,5,6,7,8,9]
return arr # 一次返回所有元素
for x in get_array():
print(x)
def get_array():
n = 0
while n < 10:
yield n
n+=1
for x in get_array():
print(x)
yield 关键字的作用类似return。区别是return之后整个函数就运行结束了,但是yield之后函数并没有结束,还会继续挂起,当你再次调用的时候会再yield下一个值。
递归
函数编程中喜欢使用递归,因为它很多时候都会让代码更简洁。不过要注意递归的性能通常都比较低,要谨慎使用。Python中递归的最大深度不能超过1000,如果你想调高这个阈值,可以通过以下代码来设置:
递归计算斐波那契数列